LogicMonitor: Understanding Why CPUBusyPercent Alert Was Not Triggered
Problem Statement:
On 15th August 2024, an incident occurred where the CPUBusyPercent alert did not trigger for one of our Production MySQL Database VMs (DB01), despite the CPU being at 100% for seven minutes. This was unexpected since the threshold settings in LogicMonitor were supposed to trigger alerts under such conditions.
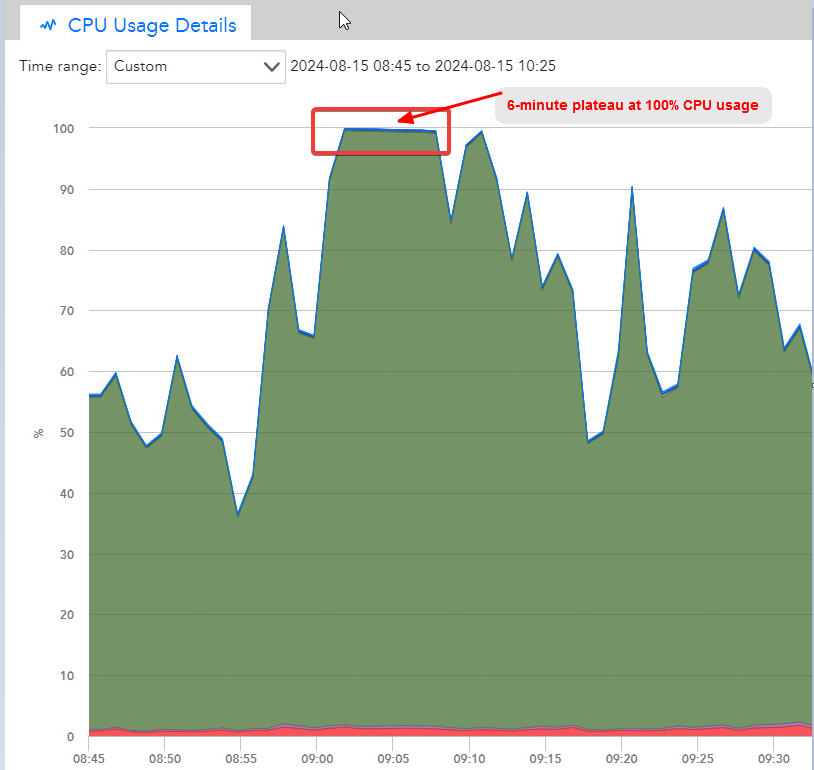
Figure 1: CPU usage plateau at 100% for 6 minutes without triggering an alert.
Analysis:
The initial investigation revealed that the CPUBusyPercent alert settings were configured to trigger an alert after five consecutive polls (which equates to 6 minutes of sustained high CPU usage). In this case, the CPU usage plateaued at 100% for exactly 6 minutes (from 9:02 to 9:08 AM), barely meeting the alert trigger criteria. However, the alert was not active long enough to be sent out due to the immediate clear interval once the CPU usage dipped below the threshold.
Upon further inspection, it was noted that the alert was indeed generated briefly at 09:08 AM, but because the CPU usage dropped shortly after, the alert was cleared immediately, and no notification was dispatched. This indicated that the default settings were not optimal for capturing such brief spikes in CPU usage.
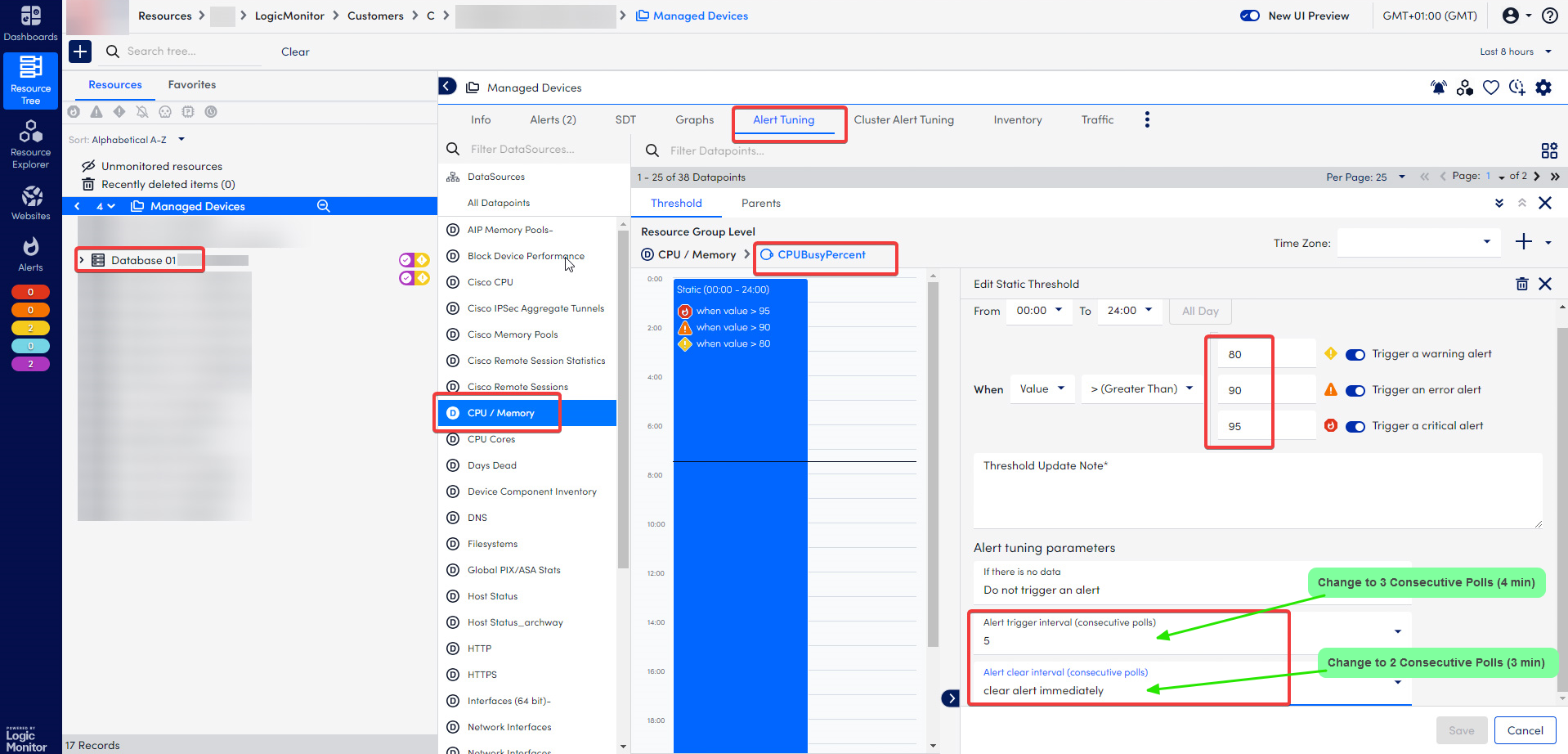
Figure 2: Previous LogicMonitor settings for CPUBusyPercent alerts.
Solution Provided:
To prevent this issue from recurring, the following adjustments were made to the alert settings:
- Alert Trigger Interval: Reduced from 5 consecutive polls (6 minutes) to 3 consecutive polls (4 minutes). This ensures that alerts are triggered more quickly when high CPU usage is detected.
- Alert Clear Interval: Changed from "Immediate" to 2 consecutive polls (2 minutes). This adjustment prevents alerts from being cleared too rapidly, allowing more time for notifications to be sent.
These changes are designed to ensure that any similar CPU usage spikes in the future will trigger a timely alert, providing better monitoring and response capabilities.
Conclusion:
This incident highlighted the importance of fine-tuning monitoring thresholds to balance between avoiding false positives and ensuring critical alerts are not missed. By adjusting the alert trigger and clear intervals, the monitoring system can now better capture and alert on CPU usage spikes, helping prevent similar issues in the future.